

L'API de reporting est-elle sécurisée ?
Toutes les données stockées dans BigQuery sont chiffrées au repos et en transit. Ainsi, lorsque les données sont stockées sur les serveurs de Google, et lorsqu'elles sont transmises entre ces serveurs et le client, elles sont protégées par un chiffrement fort.
De plus, BigQuery possède des contrôles d'accès intégrés qui vous permettent de restreindre l'accès à vos données en fonction des rôles et des autorisations utilisateurs. Cela signifie que nous indiquons précisément qui a accès à vos données, et quelles actions ces personnes sont autorisées à effectuer sur vos données.
BigQuery prend également en charge l'authentification et les autorisations par le biais de mécanismes standard, tels que OAuth 2.0 et des clés API.
L'infrastructure de Google est conçue pour être protégée contre les menaces courantes, telles que les attaques par déni de service, les violations de données et les accès non autorisés. Cela s'effectue à l'aide de plusieurs mesures de sécurité, telles que des pare-feux, des systèmes de détection des intrusions et des audits de sécurité réguliers. L'API BigQuery est conçue pour assurer la sécurité de vos données en permanence.
À quelle fréquence les données sont-elles mises à jour ?
Tous les jours. La mise à jour commence à minuit (UTC+0) avec une durée de mise à jour maximale de 12 heures. La mise à jour couvre toutes les données reçues jusqu'à minuit (UTC+0) le jour précédent.
Jusqu'à quand les données remontent-elles ?
Toutes les données historiques approuvées pour une organisation donnée sont disponibles.
Si je suis un utilisateur Direct Access, comment puis-je me connecter ?
Si vous utilisez déjà l'API GCP, le processus est simple. Il vous suffit de vous connecter et de demander les tableaux voulus via l'interface utilisateur ou l'API.
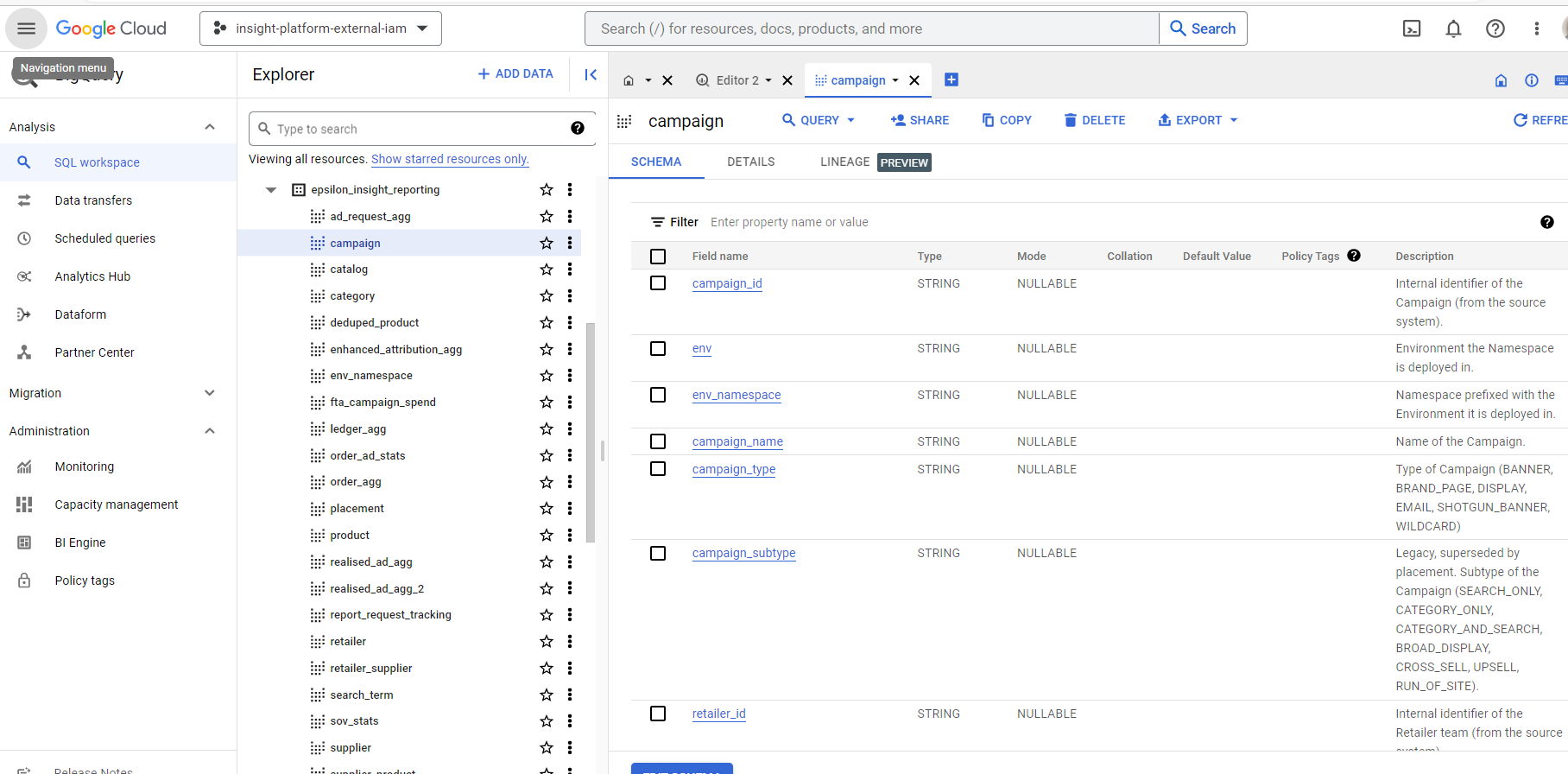
J'obtiens une erreur « L'utilisateur n'a pas l'autorisation bigquery.jobs.create dans le projet » – quelle erreur ai-je commise ?
Pour les comptes que vous nous avez fournis, CitrusAd a accordé des privilèges de visualisation BigQuery aux ensembles de données pertinents. Cela vous permet de lire les tableaux qu'ils contiennent. Dans votre projet, quelques étapes sont nécessaires pour interroger ces tableaux distants.
Supposons ce qui suit :
- Votre projet = "client-project-123456"
- Your user = [email protected]
- Ensemble de données CitrusAd : « insight-platform-external-iam.client_insight_reporting »
Vous devez :
-
Grant [email protected] the bigquery.jobs.create permission within the client-project-123456 project (not the CitrusAd project). You can do this by assigning the BigQuery Job User role.
-
When executing a query, you must run the query within your project (as you only have permissions to read the dataset within the CitrusAd project, not run queries within it). Here is how that might happen using a simple cloud shell command example (executing as [email protected]):
bq query --use_legacy_sql=false --project_id client-project-123456 'SELECT * FROM insight-platform-external-iam.client_insight_reporting.campaign limit 10;'Veuillez noter que le projet client est défini sur votre projet, et non sur insight-platform-external-iam.
Une approche similaire doit être adoptée avec tous les autres outils utilisés. Veuillez vous référer à la documentation des outils fournis pour plus d'informations, ainsi qu'aux conseils indiqués dans la documentation en ligne de GCP.
Les données CitrusAd ne sont pas dans mon emplacement, comment puis-je les obtenir ?
Il existe de nombreuses possibilités, mais il est facile de créer des ensembles de données au même endroit que les nôtres, puis d'effectuer des transformations, des requêtes, etc. dans les tableaux de ces ensembles de données, avant de les copier à l'emplacement de votre choix.

Il existe de nombreuses manières d'effectuer une copie entre des emplacements à l'aide de l'interface utilisateur, de l'outil de ligne de commande BQ et de l'API elle-même. Pour plus d'informations, veuillez consulter ces pages de documentation de Google Cloud :
- Gérer les ensembles de données | BigQuery
- référence de l’outil en ligne de commande bq
- Copier un tableau à source unique
Si je ne suis pas un utilisateur de l'API GCP, comment puis-je me connecter ?
CitrusAd vous fournira les informations de connexion pertinentes dans un fichier JSON que vous pourrez intégrer à votre mécanisme d'authentification.
Puis-je déboguer des requêtes uniquement à l'aide de l'API de reporting (et non de l'UI BigQuery) ?
Oui, l'API BigQuery renvoie un code indiquant les problèmes éventuels, et des messages d'erreur seront également disponibles.
Puis-je estimer combien coûtera une requête ?
Oui, l'API dispose d'un mécanisme permettant d'obtenir l'estimation en octets de l'analyse effectuée par la requête si celle-ci est exécutée. Vous pouvez multiplier cette estimation par la fréquence à laquelle vous effectuez la requête pour déterminer si vous allez atteindre le quota.
Plus d'informations sont disponibles dans la documentation de l'API GCP.
Requête de simulation | BigQuery | Google Cloud
Que faire si je dépasse la limite de quota ?
Veuillez vous référer à votre accord avec CitrusAd pour voir quel est votre quota. En l'absence de définition précise, la valeur par défaut est de 10 To de données de requête par mois.
Votre accord peut également mentionner un nombre maximum d'appels API par jour. En l'absence de définition précise, le nombre d’appels API par défaut est de 100 par jour.
Si vous dépassez votre quota (en matière d'analyse de données ou de nombre d'appels), nous vous contacterons pour mieux comprendre vos cas d'utilisation. Des frais de dépassement peuvent s'appliquer en fonction de votre accord.
En cas d'utilisation abusive majeure ne rentrant pas dans les conditions de votre accord (ou des limites par défaut), nous nous réservons le droit de suspendre votre accès.
Qu'est-ce qu'un exemple d'utilisation de l'API de reporting ?
Vous trouverez ci-dessous quelques exemples utilisant des méthodes courantes.
Google SDK pour Python
Cet exemple permet de :
- Se connecter à BigQuery
- Exécuter la requête
- Enregistrer le résultat dans un fichier csv
import google.cloud.bigquery as bq
import pandas as pd
bq_client = bq.Client.from_service_account_json("<REPLACE>.json")
job_config = bq.QueryJobConfig(allow_large_results=True)
query_job = bq_client.query(
'SELECT count(1) FROM insight-platform-external-iam.<REPLACE>_insight_reporting.campaign
LIMIT 1000', job_config=job_config)
df = query_job.to_dataframe(create_bqstorage_client=False)
df.to_csv(r"C:\Users\<REPLACE>\<REPLACE>.csv", index=False)
print("Run Complete")D'autres méthodes sont disponibles pour estimer les octets analysés, etc. avant d'exécuter la requête.
Veuillez vous référer à la documentation de l'API BigQuery
Si vous n'utilisez pas l'API GCP, vous pouvez référencer un fichier d'identifiants JSON via une variable d'environnement.
API Generic pour Python
import csv
import requests
from google.oauth2 import service_account
PROJECT_ID = "insight-platform-external-iam"
DATASET = "<YOUR DATASET HERE>"
END_POINT = f"https://bigquery.googleapis.com/bigquery/v2/projects/{PROJECT_ID}/queries"
QUERY = f"""
SELECT supplier_id, campaign_id, sum(ad_spend) as ad_spend, sum(clicks) as clicks
FROM `{PROJECT_ID}.{DATASET}.realised_ad_agg`
WHERE ingressed_at BETWEEN '2022-09-01' and '2022-12-31'
group by 1,2
"""
def get_token():
# With service account
credentials = service_account.Credentials.from_service_account_file('./secrets/service-account.json')
scoped_credentials = credentials.with_scopes(['https://www.googleapis.com/auth/cloud-platform'])
# Do token request
def req( method, url, headers, body, **kwargs):
resp = requests.post(url, headers=headers, data=body)
return type('obj', (object,), {'data' : resp.text, 'status': 200})
scoped_credentials.refresh(req)
return scoped_credentials.token
def run_job(token):
resp = requests.post(
END_POINT,
json={
"query": QUERY,
"useLegacySql": False
},
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
)
return resp.json()['jobReference']['jobId']
def get_query_results(job_id, token):
status_endpoint = f'{END_POINT}/{job_id}?location=australia-southeast1'
completed = False
while not completed:
response = requests.get(status_endpoint, headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
})
completed = response.json()['jobComplete']
data = response.json()
rows = data['rows']
columns = [c['name'] for c in data['schema']['fields']]
return rows, columns
def extract():
token = get_token()
job_id = run_job(token)
rows, columns = get_query_results(job_id, token)
with open('results.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(columns)
for row in rows:
writer.writerow([i['v'] for i in row['f']])
extract()Si j'utilise AWS, etc., et non Google Cloud, puis-je quand même m'authentifier et utiliser l'API ?
Oui, cela fonctionnera. Nous vous fournirons les informations de connexion pour un compte de service et vous pourrez les référencer dans votre application. Voici un exemple.
# TODO(developer): Set key_path to the path to the service account key
# file.
# key_path = "path/to/service_account.json"
credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
token = credentials.token
# use the token to do the API calls
# ...
# headers: Bearer ${token}
# ...Comment puis-je déterminer l'emplacement de chaque ensemble de données partagé avec moi ?
Cet appel API vous indiquera l'emplacement de chaque ensemble de données.
GET https://bigquery.googleapis.com/bigquery/v2/projects/insight-platform-external-iam/datasets
{
"kind": "bigquery#datasetList",
"etag": "RLU1Ww9C5FdhlcIuRHjW0A==",
"datasets": [
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_insight_reporting",
"datasetReference": {
"datasetId": "acme_insight_reporting",
"projectId": "insight-platform-external-iam"
},
"location": "australia-southeast1"
},
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_acme_analytics",
"datasetReference": {
"datasetId": "acme_acme_analytics",
"projectId": "insight-platform-external-iam"
},
"location": "us-central1"
}
]
}Avez-vous des bonnes pratiques à partager ?
De manière générale, si vous prévoyez d'utiliser une grande quantité de données, surtout si vous avez accès aux données non agrégées (requêtes, annonces réalisées, commandes, attribution améliorée, etc.), il est préférable de copier les tableaux dans votre propre entrepôt de données, puis d'effectuer les requêtes pour votre propre logique dans ces copies.
Les personnes qui utilisent peu de données peuvent simplement choisir d'effectuer des requêtes dans les tableaux directement pour obtenir des résultats précis.
Il est important de rester en dessous du quota autorisé pour assurer le bon fonctionnement.
Notez également que chaque requête peut télécharger 1 Go maximum ; autrement, vous recevrez un message d'erreur. Si vous avez besoin d'un téléchargement très volumineux, exécutez plutôt des requêtes plus petites (par exemple, un sous-ensemble de données par jour ou par fournisseur, etc.).
Que faire si j'ai besoin d'aide pour rédiger des instructions SQL appropriées ?
Créez un ticket en expliquant la requête que vous voulez effectuer, et nous vous aiderons à la vérifier en vous faisant part de nos commentaires éventuels.
Avez-vous des conseils pour utiliser le package Pandas ?
Pandas est l’un des outils d’analyse les plus populaires. Pour qu'il fonctionne, les dépendances pandas-gbq et pydata-google-auth doivent être installées.
L'extrait de code ci-dessous est un exemple fonctionnel de lecture des données d'un tableau BigQuery.
import pandas as pd
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file('path/to/the/credential/file')
query = 'select * from project.dataset.table'
dat = pd.read_gbq(
query,
project_id='project_id',
credentials=credentials
)More information about the Pandas function can be found here.
Avez-vous des conseils pour utiliser le package PySpark ?
Assuming you have a working PySpark environment, you need to provide the correct jar file for the BigQuery connector appropriate to your PySpark version. For instance, PySpark 3.2.* requires spark-3.2-bigquery-0.30.0.jar. The list of the jar files as well as practical code snippets and parameters can be found here.
L'extrait de code ci-dessous fournit un exemple d'exécution d'une requête.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('BigNumeric').config('spark.jars', 'spark-3.2-bigquery-0.30.0.jar').getOrCreate()
spark.conf.set('credentialsFile', 'path/to/the/credential/file')
spark.conf.set('viewsEnabled', 'true')
spark.conf.set('materializationProject', 'yourMaterializationProject')
spark.conf.set('materializationDataset', 'yourMaterializationDataset')
query = 'select * from project.dataset.table'
df = spark.read.format('bigquery').option('query', query).load()
df.show()IMPORTANT : le paramètre viewsEnabled doit être égal à true.
Les données dans les vues sont affichées dans des tableaux temporaires avant leur lecture par PySpark, et une autorisation bigquery.tables.create est requise. Par conséquent, vous devez fournir les valeurs materializationProject et materializionDataset, et l'utilisateur doit avoir un droit de modification.
Je reçois un message d'erreur demandant un filtre dans la requête. Que faire ?
Un filtre est obligatoire pour un tableau partitionné ; autrement, vous recevrez un message d'erreur comme celui ci-dessous :
Impossible d'interroger le tableau « dataset_id.table_id » sans filtre sur la ou les colonnes « partitioned_column » pouvant être utilisé pour l'élimination des partitions
Pour résoudre cette erreur, ajoutez simplement un filtre raisonnable couvrant la plage cible, par exemple
-- this query returns all records available since yesterday
select
*
from
dataset_id.table_id
where
ingressed_at >= date_sub(current_date, interval 1 day)Pour déterminer avec quelle colonne le tableau est partitionné (comme ingressed_at dans l'exemple ci-dessus), reportez-vous à la description du tableau concerné.
Comment puis-je demander l'accès ?
Processus
Vous devez ouvrir un ticket, et les critères d'éligibilité doivent être convenus par écrit.
Nous contactons le candidat pour identifier le niveau d'accès et les paramètres de sécurité requis, et pour déterminer les quotas et les coûts pouvant s'appliquer.
Critères d'éligibilité
Un candidat doit remplir les critères suivants pour être considéré comme éligible à l'accès à l'API de reporting : -
Généralités
- Le candidat ne peut demander l'accès aux données que pour les espaces de noms CitrusAd et les équipes dont il est déjà membre ou auxquels il a déjà accès. Le candidat doit préciser pour lequel des cas de figure suivants il postule (et fournir la preuve de son accès existant) :
- Niveau Environnement (une implémentation complète de la plateforme CitrusAd est dédiée au candidat).
- Niveau Espace de noms (le candidat a l'autorisation de voir toutes les équipes, à la fois des détaillants et des fournisseurs, au sein d'un espace de noms individuel ou d'une liste d'espaces de noms).
- ID spécifique de l'équipe du détaillant ou niveau du groupe.
- ID spécifique de l'équipe du fournisseur ou niveau du groupe.
- En outre, un intégrateur peut accéder à l'ID de l'équipe d'un fournisseur spécifique ou au niveau d'un groupe PLUS aux catalogues complets des produits d'un détaillant, si le détaillant l'accepte au cas par cas.
- Les données des informations transactionnelles ne peuvent être fournies qu'aux candidats éligibles aux Critères généraux 1a ou 1b.
- Les candidats qui ne remplissent pas les conditions requises pour accéder aux données des informations transactionnelles auront uniquement accès aux données des informations préagrégées. Les données seront agrégées dans des résumés quotidiens (avec UTC+0 comme fuseau horaire d'agrégation).
- Les candidats uniquement éligibles aux Critères généraux 1d ne pourront pas recevoir les données des requêtes d'annonce (par opposition aux données des annonces réalisées, qui seront fournies). Les données des produits seront fournies pour les Produits spécifiques mis en avant dans les annonces réalisées par le fournisseur, SAUF pour les intégrateurs qui peuvent recevoir les catalogues de produits des détaillants lorsque convenus par un détaillant au cas par cas.
- Les données dimensionnelles ne peuvent inclure que les versions actuelles des enregistrements en question. Le suivi des modifications historiques devra être effectué par le candidat selon ses besoins.
- Les données sont mises à jour quotidiennement, au plus tard à minuit (UTC+0) pour les données jusqu'au et incluant le jour précédent (UTC+0).
- Il est entendu que l'accès est en lecture seule par nature. L'API ne doit pas être utilisée pour créer des objets dans notre entrepôt de données à aucune fin.
- Tout mélange avec d'autres sources de données doit être effectué dans l'environnement du candidat.
- Le candidat doit disposer d'un SDK (ou équivalent) pour accéder à l'API Google BigQuery.
- Le candidat doit avoir de bonnes connaissances du SQL.
- Le candidat doit être familiarisé avec les concepts de CitrusAd ; si ce n'est pas le cas, il prendra des dispositions pour suivre la formation standard sur les produits, qui devra être fournie par son responsable du service client ou son responsable du compte technique.
- Sur la base des documents fournis, le candidat doit développer ses propres solutions. Si un problème est détecté avec une requête SQL qui ne se déroule pas comme prévu au regard de la documentation, un ticket doit être ouvert via les canaux de support habituels. Les informations suivantes doivent être fournies.
- Le compte via lequel la connexion est établie.
- La requête SQL exacte effectuée.
- Une description détaillée des messages d'erreur.
- Si le candidat est un détaillant, les impressions/clics/commandes devront être fournis à la plateforme CitrusAd afin qu'une image complète du cycle de vie de l'annonce puisse être établie.
- CitrusAd se réserve le droit de modifier le schéma de manière ponctuelle. Ces modifications impliquent généralement l'ajout de nouvelles colonnes aux tableaux et vues existants, et sont rétrocompatibles. Les candidats doivent structurer leur SQL pour nommer les colonnes plutôt que d'utiliser des caractères génériques, etc. Dans le cas où un changement implique d'abandonner une colonne ou un tableau, CitrusAd donnera un préavis d'au moins 12 semaines afin d'annoncer la modification avant son implémentation. Les notifications seront envoyées via des communications standard adressées aux utilisateurs de la plateforme.
Les candidats ne sont pas tenus d'être des utilisateurs de la Google Cloud Platform (GCP) ; cependant, d'autres critères existent selon que le candidat utilise ou non l'API GCP.
Candidat qui n'utilise pas l'API GCP
Sauf accord contraire, CitrusAd fournira des informations de connexion pour un seul compte de service dans notre environnement au candidat.
Sauf accord contraire, les conditions par défaut suivantes s'appliquent :
- Un maximum de 100 appels API par jour.
- No more than 10TB of data scans per month (note, the API has a way of estimating the query scan size prior to execution, refer to Google documentation Dry run query | BigQuery | Google Cloud).
- Si le candidat qui n'utilise pas l'API GCP dépasse les critères 1 et/ou 2, CitrusAd se réserve le droit de suspendre l'accès à sa seule discrétion.
- Aucun appel API individuel ne peut télécharger plus de 1 Go de données à la fois.
Comment décoder le fichier du compte de service ?
Les informations d'identification du compte de service vous seront fournies dans un format encodé en Base64 pour une transmission sécurisée. Vous devrez les décoder avant de l'utiliser. Voici des exemples de la manière de décoder le fichier :
Utilisation de bash :
# Replace encoded-credentials.txt with the file containing your base64 encoded credentials
base64 -d encoded-credentials.txt > service-account.jsonUtilisation de Python :
import base64
# Replace encoded_credentials with your base64 encoded string
with open('encoded-credentials.txt', 'r') as f:
encoded_credentials = f.read()
decoded_credentials = base64.b64decode(encoded_credentials)
with open('service-account.json', 'wb') as f:
f.write(decoded_credentials)Après le décodage, vous aurez un fichier service-account.json que vous pourrez utiliser avec les bibliothèques client BigQuery, comme illustré dans les exemples précédents.
Candidat qui utilise l'API GCP
Sauf accord contraire, le candidat fournira à CitrusAd les informations d'au moins 5 comptes GCP afin que nous puissions attribuer l'accès requis.
Veuillez noter que le rôle BigQuery Job User (roles/bigquery.jobUser) doit être affecté au compte.
Les restrictions suivantes s'appliquent :
- Un maximum de 100 appels API par jour.
- Si le candidat qui utilise l'API GCP dépasse le critère 1, CitrusAd se réserve le droit de suspendre l'accès à sa seule discrétion.
- Aucun appel API individuel ne peut télécharger plus de 1 Go de données.
Glossaire
Environnement
Le nom de l'environnement physique dans lequel la plateforme CitrusAd est déployée. Chacun héberge un ou plusieurs espaces de noms.
Espace de noms
Un regroupement logique de toutes les entités qui font partie d'une mise en œuvre de la solution CitrusAd. Sont inclus les équipes et tous les objets appartenant à des équipes. En général, un espace de noms peut être composé d'un détaillant (équipe), de plusieurs fournisseurs (équipes) et d'utilisateurs dans chaque équipe, ainsi que d'autres configurations associées (catalogues des détaillants, campagnes configurées par les fournisseurs, etc.). Les équipes (et ce qu'elles possèdent) appartiennent exclusivement à un seul espace de noms (aucune équipe ne peut exister dans plusieurs espaces de noms).
Utilisateur
L'identifiant unique d'un utilisateur dans le système CitrusAd. Une seule adresse e-mail peut comporter plusieurs userIds. Chaque userId est unique à chaque espace de noms. Chaque utilisateur disposera d'un prénom, d'un nom, d'une adresse e-mail et d'un identifiant. Un utilisateur peut être membre et accéder à plusieurs équipes sur la plateforme CitrusAd.
Équipe
Une équipe au sein du système CitrusAd. Peut être un fournisseur (annonceur) ou un détaillant. Les équipes de fournisseurs créeront généralement des campagnes, alors que les détaillants les examineront et exécuteront des fonctions administratives. Un utilisateur au sein du système CitrusAd peut être membre d'une ou plusieurs équipes. En règle générale, une équipe est associée à des utilisateurs, des campagnes et des portefeuilles.
Fournisseur
Une équipe de fournisseurs au sein du système CitrusAd. Bien souvent, un fournisseur peut être la société mère d'une marque ou plusieurs équipes pour chaque marque. Les fournisseurs ont pour habitude de gérer les campagnes, les soldes des portefeuilles, etc.
Détaillant
Une équipe de détaillants au sein du système CitrusAd. La plupart des espaces de noms n'ont qu'une seule équipe de détaillants. Bien souvent, les détaillants gèrent les catalogues de produits, examinent les campagnes, etc.
Campagne
Une campagne unique configurée avec une stratégie de placement et de ciblage pour une sélection précise de produits. À titre d'exemple, une campagne dans le système CitrusAd pourrait promouvoir les produits A et B ciblant les termes de recherche « chocolat » et « chocolats » avec une enchère maximale définie à 0,60 $. En règle générale, une équipe gère plusieurs campagnes.
Catalogue
Le catalogue de produits unique d'un détaillant dans le système CitrusAd. Souvent, un détaillant synchronise un seul catalogue de produits avec CitrusAd, dans un seul espace de noms. Un catalogue contient une liste de tous les produits du catalogue du détaillant, leur nom, leur marque, leurs catégories et d'autres attributs pertinents ingérés dans le système CitrusAd.
Produit
Un produit unique dans le système CitrusAd. Il est associé à un code produit unique, synchronisé dans le catalogue de produits. Un produit peut avoir des attributs tels que la catégorie, la taxonomie, la marque, etc.
Portefeuille
Un portefeuille dans le système CitrusAd qui stocke les fonds d’un annonceur dans le but d’effectuer des paiements (par exemple, payer pour les annonces réalisées). Chaque portefeuille est associé à un code de devise unique et ne peut être dépensé que pour les catalogues possédant ce même code. Un portefeuille appartient à une équipe, qui peut d'ailleurs en posséder autant qu'elle le souhaite. Un portefeuille peut être archivé. Dans ce cas, il sera uniquement affiché ou masqué sur la plateforme, et les crédits qu'il contient pourront toujours être dépensés.
Grand livre
Un grand livre d'événements ayant entraîné une transaction dans le système CitrusAd. Il s'agit généralement d'événements publicitaires tels que des impressions ou des clics sur des produits sponsorisés ou des bannières publicitaires (générant un mouvement débiteur). Il peut également s'agir de recharges et d'ajustements de soldes par un fournisseur (générant un mouvement créditeur). Chaque événement est associé à un « motif » ; Produits sponsorisés, Bannières publicitaires, Recharge.
Requête
Une requête faite au système CitrusAd en matière d'annonces. Dans la requête, le détaillant spécifie un placement et un contexte, tel que le sessionId d'un client ou les filtres pertinents pour la demande. Selon la requête, CitrusAd enverra des publicités d'un type d'annonce pertinent (par exemple, catégorie ou terme de recherche) au détaillant pour qu'il les présente au client.
Annonce (réalisée)
Une annonce est un événement publicitaire unique renvoyé à un détaillant en vue d'être diffusé à son client. Il devient une annonce réalisée lorsque le détaillant renvoie une confirmation indiquant que l'annonce a reçu des impressions (confirmation explicite que l'annonce a été réellement utilisée, c'est-à-dire réalisée). Dans le système CitrusAd, chaque annonce possède un identifiant d'annonce réalisée, qui est une référence pour cet événement unique.
Catégorie
Une catégorie est une page sur le site du détaillant et qui fait partie de sa taxonomie, telle que « Viennoiserie » ou « Produits laitiers ». Un détaillant émet généralement des requêtes publicitaires sur une page de catégorie auprès de CitrusAd, en spécifiant cet attribut pertinent. Si CitrusAd fait correspondre une campagne active et valide à la catégorie, des annonces seront renvoyées.
Terme de recherche
Un terme de recherche saisi par un client sur le site Web du détaillant. Ce terme de recherche est ensuite envoyé à CitrusAd pour demander des annonces pertinentes. Si CitrusAd dispose d'une campagne active et valide pour ce terme de recherche, des annonces seront renvoyées.
Commande
Une commande unique dans le système du détaillant, synchronisée avec CitrusAd. Une seule commande peut contenir plusieurs articles (tout comme le panier d'un client). Dès qu'une commande client est finalisée, elle est envoyée à CitrusAd afin d'alimenter l'attribution du système. Le retour sur les dépenses publicitaires (ROAS) et d'autres ICP importants peuvent ensuite être fournis aux détaillants et aux annonceurs.
Attribution
L'attribution est un processus exécuté dans le système CitrusAd. Il permet d'attribuer des annonces diffusées à un client à une commande passée. En règle générale, on considère habituel le parcours client suivant : le client voit une annonce (impression), il clique dessus (clic), ajoute le produit à son panier et l'achète (conversion). La commande est « attribuée » à l'annonce unique sur laquelle le client a cliqué. Pour qu'une commande soit attribuée dans le système CitrusAd, le client doit interagir avec l'annonce (via une vue ou un clic) puis acheter un article associé à l'annonce. CitrusAd utilise généralement un « sessionId » pour attribuer des commandes aux annonces, où le détaillant spécifie un « sessionId » dans tous les points de contact pertinents d'un parcours publicitaire. C'est ainsi que CitrusAd peut conclure qu'une seule annonce, diffusée à un seul client, a donné lieu à une commande spécifique.
Dates
Si elles sont agrégées, toutes les données sont converties dans le fuseau horaire UTC+0.
Limite
Les mises en œuvre sur la plateforme CitrusAd impliquent souvent que le détaillant demande plus d'annonces qu'il n'en aura réellement (c'est-à-dire qui seront réalisées). D'un point de vue analytique, cela peut fausser les résultats de certains indicateurs.
Par exemple, si une requête pour 20 annonces (AdType=Product) a été émise et que la plateforme a diffusé 2 annonces en réponse, on obtient un « taux de remplissage » de 10 % pour la requête (2 sur 20). Toutefois, en pratique, s'il est entendu que seules 4 annonces sont susceptibles d'être utilisées (réalisé), il serait préférable d'interpréter que le taux de remplissage est de 50 % (2 sur 4).
C'est pourquoi la notion de limite est utilisée dans le cadre du reporting.
La limite est définie par détaillant. On applique une limite pour les annonces de produits et une autre pour les bannières publicitaires (étant donné que les requêtes d'annonces de produits demandent et utilisent généralement bien plus d'annonces que de bannières).
Pour reprendre l'exemple ci-dessus, si la limite appliquée au produit = 4 pour le détaillant, voici les indicateurs liés à la requête qui pourraient être renvoyés : -
NumAdRequests = 1
NumAdsRequested = 20
CappedNumAdsRequested = 4
NumAdsServed = 2
CappedNumAdsServed = 2
Notez que dans le cas où 5 annonces seraient diffusées (c'est-à-dire que les annonces diffusées excèderaient la limite), on obtiendrait ces deux indicateurs : -
NumAdsServed = 5
CappedNumAdsServed = 4 (rééquilibrage avec la limite)
Les limites ne sont pas obligatoires. Si elles ne sont pas spécifiées, les résultats limités et non limités seront identiques.
Attribution améliorée
La plateforme CitrusAd réalise des attributions comme indiqué dans la section Attribution (voir ci-dessus).
Le sous-système de reporting peut également détecter et signaler d'autres scénarios d'attribution en fonction du détaillant (attribution améliorée).
Les scénarios sont les suivants :
- Impression – Attribution d'une vue
- Une commande a été attribuée à une annonce qui a été vue pour le même produit avec le même identifiant de session (c'est-à-dire, une impression et non un clic).
- Attribution de clic de halo
- Une commande a été attribuée à une annonce sur laquelle un clic a été effectué pour un produit appartenant au même niveau de halo, avec le même ID de session. Le niveau de halo le plus courant est Marque (on considère alors que le produit de l'annonce et le produit de la commande sont différents, mais appartiennent à la même marque). Il existe d'autres types de halo en fonction de la mise en œuvre. Par exemple, le halo peut être plus spécifique et exiger que l'annonce et la commande correspondent aux produits ayant une catégorie commune en plus d'une marque commune. La taxonomie du détaillant définie par produit dans le catalogue est utilisée pour définir ce niveau de détail supplémentaire dans le halo.
Version: 1ace13f